
Supervised DR with a Custom Loss¶
In this example, we’ll set up a supervised dimensionality reduction routine based on t-SNE. First, we’ll create a ParaDime routine for plain parametric t-SNE, which is similar to how the predefined ParametricTSNE is set up. Afterwards, we’ll explore the effects of an additional custom loss that takes class label information into account. This additional loss is based on the triplet margin loss.
The Cover Type Dataset¶
We will use our custom routine to create embeddings of the forest cover type dataset. This dataset consists of cartographic variables that can be used to predict the type of forest that covers an area. Each data point has 54 attributes and is labeled as one of 7 types of forest.
First, let’s import the relevant submodules from ParaDime, along with a couple of other packages. We’ll take the covertype dataset from sklearn, and we’ll also use sklearn’s TSNE to see how our parametric verison compares against a non-parametric one.
[2]:
import numpy as np
import torch
import sklearn.datasets
import sklearn.decomposition
import sklearn.manifold
import sklearn.preprocessing
from matplotlib import pyplot as plt
import paradime.dr
import paradime.relations
import paradime.transforms
import paradime.loss
import paradime.utils
paradime.utils.seed.seed_all(42);
[3]:
covertype = sklearn.datasets.fetch_covtype()
The covertype dataset is highly unbalanced, i.e., it has many more entries for certain classes than others. In this example, we want to use a balanced subset of the dataset. To obtain this subset, we first count how often each class is present. We then invert these counts to compute weights and draw 7000 sample indices with a WeightedRandomSampler, which should lead to a roughly balanced dataset.
[4]:
_, counts = np.unique(covertype.target, return_counts=True)
weights = np.array([ 1/counts[i-1] for i in covertype.target ])
[5]:
indices = list(torch.utils.data.WeightedRandomSampler(weights, 7000))
Finally, we standardize the data. Note that in this example we only use the first ten features of the covertype dataset, which are all numerical. The remaining 44 attributes are categorical and would require a slightly special treatment for use with a NN model.
[6]:
raw_data = covertype.data[indices,:10]
scaler = sklearn.preprocessing.StandardScaler()
scaler.fit(raw_data)
data = scaler.transform(raw_data)
The class labels in the covertype dataset are integers from 1 to 7. Here’s how they map to the actual class names:
[7]:
label_to_name = {
1: "Spruce/fir",
2: "Lodgepole pine",
3: "Ponderosa pine",
4: "Cottonwood/willow",
5: "Aspen",
6: "Douglas-fir",
7: "Krummholz",
}
Regular t-SNE¶
Now that we have our data ready, let’s look at a regular t-SNE of our subset:
[8]:
tsne = sklearn.manifold.TSNE(perplexity=200, init="pca")
emb = tsne.fit_transform(data)
c:\Users\Andreas\miniconda3\envs\ml\lib\site-packages\sklearn\manifold\_t_sne.py:805: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(
c:\Users\Andreas\miniconda3\envs\ml\lib\site-packages\sklearn\manifold\_t_sne.py:991: FutureWarning: The PCA initialization in TSNE will change to have the standard deviation of PC1 equal to 1e-4 in 1.2. This will ensure better convergence.
warnings.warn(
[9]:
paradime.utils.plotting.scatterplot(emb,
labels=[ label_to_name[i] for i in covertype.target[indices]],
legend_options={"loc": 1}
)
[9]:
<AxesSubplot:>

While some classes are mixed together quite a bit, we see an overall structure of ‘bands’ of items that roughly correspond with the classes.
Unsupervised Parametric t-SNE¶
Let’s now set up a ParaDime routine that implements a parametric version of t-SNE.
While older implementations of t-SNE use a full pariwise distance matrix, newer implementations use a neighbor-based approximate distance matrix , similar to UMAP. In ParaDime, NeighborBasedPDist implements such an approximate distance matrix, and we use it as global relations here. In t-SNE, the pairiwse distances are rescaled based on a parameter called perplexity. Essentially, distances are transformed to probabilities of neighborhood using a Gaussian kernel, and the kernel width for a given data point is set in such a way that the entropy of the resulting neighborhood distribution matches the binary logarithm of the perplexity. In simple terms, the perplexity can be understood as a smooth measure of how many nearest neighbors are taken into account for the embedding. We use a perplexity value of 200 here. The resulting probability matrix is then symmetrized and normalized.
[10]:
tsne_global_rel = paradime.relations.NeighborBasedPDist(
transform=[
paradime.transforms.PerplexityBasedRescale(
perplexity=200, bracket=[0.001, 1000]
),
paradime.transforms.Symmetrize(),
paradime.transforms.Normalize(),
]
)
For the batch-wise relations, t-SNE uses pairwise distances rescaled using a Student’s t-distribution (hence the name). The probabilities (this time of neighborhood in the low-dimensional space) are again normalized.
[11]:
tsne_batch_rel = paradime.relations.DifferentiablePDist(
transform=[
paradime.transforms.StudentTTransform(alpha=1.0),
paradime.transforms.Normalize(),
paradime.transforms.ToSquareTensor(),
]
)
Because t-SNE is usually initialized with PCA, we set up a derived data object that will later compute the first two components of our training data.
[12]:
def pca(x):
return sklearn.decomposition.PCA(n_components=2).fit_transform(x)
derived = paradime.dr.DerivedData(pca)
Finally, we define two training phases: one for the initilaization, using a PositionLoss on the PCA coordinates; and one for the main embedding, using a RelationLoss on the global and batch-wise relations (i.e., probabilities). We’ll reuse the initialization phase later.
[13]:
losses = {
"init": paradime.loss.PositionLoss(position_key="pca"),
"embedding": paradime.loss.RelationLoss(
loss_function=paradime.loss.kullback_leibler_div
),
}
tsne_init = paradime.dr.TrainingPhase(
name="pca_init",
loss_keys=["init"],
batch_size=500,
epochs=10,
learning_rate=0.01,
)
tsne_main = paradime.dr.TrainingPhase(
name="embedding",
loss_keys=["embedding"],
batch_size=500,
epochs=40,
learning_rate=0.02,
report_interval=2,
)
We can now set up our routine and train it:
[14]:
pd_tsne = paradime.dr.ParametricDR(
global_relations=tsne_global_rel,
batch_relations=tsne_batch_rel,
derived_data={"pca": derived},
losses=losses,
in_dim=10,
out_dim=2,
hidden_dims=[100,50],
use_cuda=True,
verbose=True,
)
pd_tsne.add_training_phase(tsne_init)
pd_tsne.add_training_phase(tsne_main)
pd_tsne.train(data)
2022-12-05 14:10:25,753: Initializing training dataset.
2022-12-05 14:10:25,755: Computing derived data entry 'pca'.
2022-12-05 14:10:25,762: Adding entry 'pca' to dataset.
2022-12-05 14:10:25,763: Computing global relations 'rel'.
2022-12-05 14:10:25,764: Indexing nearest neighbors.
2022-12-05 14:10:56,693: Calculating probabilities.
2022-12-05 14:10:58,633: Beginning training phase 'pca_init'.
2022-12-05 14:11:02,928: Loss after epoch 0: 11.940744780004025
2022-12-05 14:11:03,440: Loss after epoch 5: 0.014664343849290162
2022-12-05 14:11:04,025: Beginning training phase 'embedding'.
2022-12-05 14:11:07,246: Loss after epoch 0: 0.0502334909979254
2022-12-05 14:11:13,415: Loss after epoch 2: 0.04354745685122907
2022-12-05 14:11:19,372: Loss after epoch 4: 0.04269221145659685
2022-12-05 14:11:25,082: Loss after epoch 6: 0.042116042925044894
2022-12-05 14:11:30,822: Loss after epoch 8: 0.04153931140899658
2022-12-05 14:11:36,605: Loss after epoch 10: 0.04116899846121669
2022-12-05 14:11:42,741: Loss after epoch 12: 0.04075181018561125
2022-12-05 14:11:48,653: Loss after epoch 14: 0.040642548352479935
2022-12-05 14:11:54,616: Loss after epoch 16: 0.040189651073887944
2022-12-05 14:12:00,671: Loss after epoch 18: 0.0402443700004369
2022-12-05 14:12:06,879: Loss after epoch 20: 0.04007487837225199
2022-12-05 14:12:13,233: Loss after epoch 22: 0.04005487961694598
2022-12-05 14:12:19,617: Loss after epoch 24: 0.03948781872168183
2022-12-05 14:12:26,066: Loss after epoch 26: 0.03957234276458621
2022-12-05 14:12:32,160: Loss after epoch 28: 0.039542140206322074
2022-12-05 14:12:38,549: Loss after epoch 30: 0.03934720088727772
2022-12-05 14:12:44,741: Loss after epoch 32: 0.0395183025393635
2022-12-05 14:12:50,727: Loss after epoch 34: 0.03938790480606258
2022-12-05 14:12:56,677: Loss after epoch 36: 0.039022325072437525
2022-12-05 14:13:02,740: Loss after epoch 38: 0.03930587996728718
Once the training has completed we can visualize our parametric t-SNE of the covertype subset:
[15]:
paradime.utils.plotting.scatterplot(
pd_tsne.apply(data),
labels=[label_to_name[i] for i in covertype.target[indices]],
legend_options={"loc": 1}
)
[15]:
<AxesSubplot:>
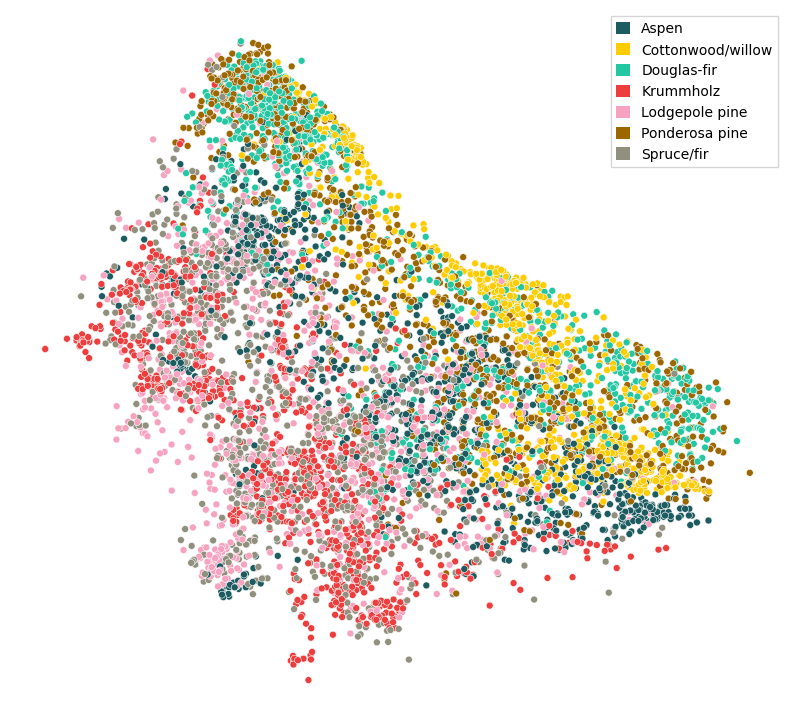
Notice how the overall shape and banding structure is very similar to the “exact” t-SNE.
Supervised Parametric t-SNE¶
Since the class clusters overlap quite strongly, we would like to see if we can make them a bit more compact by introducing a supervision in our routine. This will make use of the class labels to artificially separate the class clusters.
One promising type of loss for this task is the so-called triplet loss. It basically looks at triplets of datapoints, where one datapoint is the so called anchor, one is a positive example (with the same label as the anchor), and one a negative example (with a different label). The loss then tries to maximize the difference of the distance between anchor and positive, and anchor and negative examples. This essentiall pulls points with equal labels closer together, while pushing points with different labels further apart.
The triplet loss is implemented in PyTorch as TripletMarginLoss. To make use of it in a ParaDime routine, we have to make sure it is applied correctly to triplets of data samples. We do this by writing a custom Loss class:
[16]:
class TripletLoss(paradime.loss.Loss):
"""Triplet loss for supervised DR.
To be used with negative edge sampling with sampling rate 1.
"""
def __init__(self, margin=1.0, name=None):
super().__init__(name)
self.margin = margin
def forward(self, model, global_relations, batch_relations, batch, device):
data = batch['from_to_data'].to(device)
# data consists of [[a0, a0, a1, a1, ...], [p0, n0, p1, n1, ...]]
anchor = model(data[0,::2])
positive = model(data[1,::2])
negative = model(data[1,1::2])
loss = torch.nn.TripletMarginLoss(margin=self.margin)
return loss(anchor, positive, negative)
In a custom ParaDime Loss, we basically only have to define a forward method for the loss with a given call signature. As explained in the section about Building Blocks of a ParaDime Routine, the loss gets passed the model, the computed global relation data, the batch-relation “recipes”, the batch of data, and the device on which the model lives. To obtain triplets, we can make use of the negative edge sampling provided by
ParaDime. A batch of negative-edge sampled dataconsists of 1 + n copies of each data point, together with one actually neighboring sample and n non-neighboring samples (n is the negative sampling rate). Whether or not two data points are consideres as neighbors is governed by a some global relations between data points. If we construct our negative edge sampler with a negative samplnig rate of 1 and with the correct relations, we’ll obtain triplets directly in the batch’s
'from_to_data' attribute.
Let’s now construct these relations separately. In our case, two datapoints should be considered “neighbors” if they have the same target label. We’ll construct a matrix of zeros and ones for our data subset, where 1 means “same label” and 0 means “different label”:
[17]:
labels = covertype.target[indices]
same_label = (np.outer(labels, np.ones_like(labels))
- np.outer(np.ones_like(labels), labels) == 0).astype(float)
All that’s left to do now is to: 1. Add the above relations as a second global relation entry to our routine (we can use the Precomputed relations interface); 2. configure our main training phase to use negative edge sampling; 3. tell it to use the above relations as a basis for sampling; and 4. change the loss from a pure t-SNE loss to a CompoundLoss with our TripletLoss.
[20]:
new_losses = {
"init": paradime.loss.PositionLoss(position_key="pca"),
"embedding": paradime.loss.RelationLoss(
loss_function=paradime.loss.kullback_leibler_div,
global_relation_key="tsne",
),
"triplet": TripletLoss(),
}
super_tsne = paradime.dr.ParametricDR(
global_relations={
"tsne": tsne_global_rel,
"same_label": paradime.relations.Precomputed(same_label),
},
batch_relations=tsne_batch_rel,
losses=new_losses,
derived_data={"pca": derived},
in_dim=10,
out_dim=2,
hidden_dims=[100, 50],
use_cuda=True,
verbose=True,
)
super_tsne.add_training_phase(tsne_init)
super_tsne.add_training_phase(
name="embedding",
loss_keys=["embedding", "triplet"],
loss_weights=[700, 1],
sampling="negative_edge",
neg_sampling_rate=1,
edge_rel_key="same_label",
batch_size=300,
epochs=40,
learning_rate=0.02,
report_interval=2,
)
super_tsne.train(data)
2022-12-05 14:20:00,668: Initializing training dataset.
2022-12-05 14:20:00,672: Computing derived data entry 'pca'.
2022-12-05 14:20:00,679: Adding entry 'pca' to dataset.
2022-12-05 14:20:00,680: Computing global relations 'tsne'.
2022-12-05 14:20:00,681: Indexing nearest neighbors.
2022-12-05 14:20:16,606: Calculating probabilities.
2022-12-05 14:20:17,970: Computing global relations 'same_label'.
2022-12-05 14:20:17,972: Beginning training phase 'pca_init'.
2022-12-05 14:20:18,083: Loss after epoch 0: 10.884016819298267
2022-12-05 14:20:18,563: Loss after epoch 5: 0.017522574809845537
2022-12-05 14:20:19,907: Beginning training phase 'embedding'.
2022-12-05 14:20:22,939: Loss after epoch 0: 32.01252293586731
2022-12-05 14:20:29,014: Loss after epoch 2: 30.3692524433136
2022-12-05 14:20:34,762: Loss after epoch 4: 29.99975609779358
2022-12-05 14:20:40,583: Loss after epoch 6: 29.942914247512817
2022-12-05 14:20:46,349: Loss after epoch 8: 30.27841305732727
2022-12-05 14:20:52,261: Loss after epoch 10: 30.140958786010742
2022-12-05 14:20:58,256: Loss after epoch 12: 29.480865478515625
2022-12-05 14:21:04,229: Loss after epoch 14: 29.68207097053528
2022-12-05 14:21:10,285: Loss after epoch 16: 29.571425676345825
2022-12-05 14:21:16,148: Loss after epoch 18: 29.922452688217163
2022-12-05 14:21:22,078: Loss after epoch 20: 28.734748125076294
2022-12-05 14:21:28,032: Loss after epoch 22: 28.97758436203003
2022-12-05 14:21:33,939: Loss after epoch 24: 29.372246980667114
2022-12-05 14:21:39,932: Loss after epoch 26: 29.462066411972046
2022-12-05 14:21:45,902: Loss after epoch 28: 28.646995782852173
2022-12-05 14:21:51,803: Loss after epoch 30: 28.690879583358765
2022-12-05 14:21:57,740: Loss after epoch 32: 29.042333364486694
2022-12-05 14:22:03,682: Loss after epoch 34: 29.24993133544922
2022-12-05 14:22:09,649: Loss after epoch 36: 28.52255344390869
2022-12-05 14:22:15,668: Loss after epoch 38: 28.926764726638794
The only tricky part here is to set the correct weight for each loss component in the compound loss. One way to do this is to start with some best guess for the weights, train the routine, and then inspect both the total loss’s and the individual losses’ histories. You can access the history of the total loss via super_tsne.training_phases[1].loss.history, and of the weighted histories of the individual losses via super_tsne.training_phases[1].loss.detailed_history().
[21]:
paradime.utils.plotting.scatterplot(
super_tsne.apply(data),
labels=[label_to_name[i] for i in covertype.target[indices]],
)
[21]:
<AxesSubplot:>
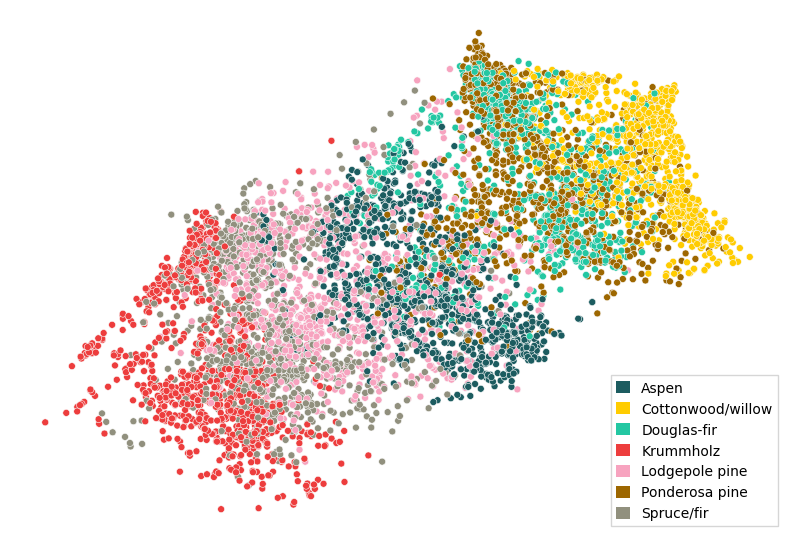
Clearly, the triplet loss pulled apart the different classes, while the overall structure (the “bands” and their relative ordering) was preserved due to the compound loss with the t-SNE component.