
Simple Usage¶
ParaDime is a flexible framework for specifiying parametric dimensionality reduction routines. A routine basically consists of a neural network, a dataset, and some instructions about what exactly ParaDime should do yith your data to reduce its dimensionality.
ParaDime has a flexible API with several predefined classes for each part of a routine, and each part can be fully customized by extending these existing classes. If you want to learn more about what exactly makes up a routine, see the Building Blocks page.
But for now, the easiest way to get started with ParaDime is to use on of the predefined routines. In the following short tutorial, we are going to train one of the predefined ParaDime routines to reduce the dimensionality of data from the MNIST dataset of handwritten digits.
Importing ParaDime and Loading the Dataset¶
First, we import the routines submodule of ParaDime, which includes the predefined routines. We also import ParaDime’s utils subpackage, which implements a scatterplot function that we are later going to use. Finally, we import torchvision, which gives us convenient access to the MNIST dataset.
[2]:
import paradime.routines
import paradime.utils
import torchvision
mnist = torchvision.datasets.MNIST(
'../data',
train=True,
download=True,
)
mnist_data = mnist.data.reshape(-1, 28*28) / 255.
num_items = 5000
Note that we have already flattened the image data into vectors of length 784 and normalized the values to a range between 0 and 1. num_items is the size of the MNIST subset that we are going to use for training our routine.
Setting Up a Predefined Routine¶
We now create an instance of a parametric version of the t-SNE algorithm:
[3]:
dr = paradime.routines.ParametricTSNE(
in_dim=28*28,
perplexity=100,
epochs=40,
use_cuda=True,
verbose=True,
)
When initializing a routine, ParaDime only needs minimal information to set up the underlying neural network. In this case ParaDime infers all the necessary information from the dataset that we pass. For more info on the default model construction, see the section about Models. We tell ParaDime that the main part of the traingin should go on for 40 epochs, and we would like to use the GPU for training (use use_cuda = False or comment out this line, if you
don’t have CUDA installed.) Finally, the verbose flag tells ParaDime to log some information about what is going on behind the scenes.
You might have noticed that we also pass a perplexity value, which is specific to the t-SNE algorithm.
Training the Routine and Visualizing the Results¶
Since any other necessary bulding blocks are already predefined in this case, all that’s left to do is to train the model. To do this, we simply call:
[4]:
dr.train(mnist_data[:num_items])
2022-12-01 14:51:41,783: Initializing training dataset.
2022-12-01 14:51:41,785: Computing derived data entry 'pca'.
2022-12-01 14:51:41,895: Adding entry 'pca' to dataset.
2022-12-01 14:51:41,896: Computing global relations 'rel'.
2022-12-01 14:51:41,898: Indexing nearest neighbors.
2022-12-01 14:52:03,566: Calculating probabilities.
2022-12-01 14:52:04,688: Beginning training phase 'pca_init'.
2022-12-01 14:52:06,790: Loss after epoch 0: 21.78548312187195
2022-12-01 14:52:07,225: Loss after epoch 5: 0.14978669676929712
2022-12-01 14:52:07,563: Beginning training phase 'embedding'.
2022-12-01 14:52:08,149: Loss after epoch 0: 0.04899946367368102
2022-12-01 14:52:10,960: Loss after epoch 5: 0.038321922766044736
2022-12-01 14:52:13,673: Loss after epoch 10: 0.034834683407098055
2022-12-01 14:52:16,176: Loss after epoch 15: 0.03364448738284409
2022-12-01 14:52:18,904: Loss after epoch 20: 0.03243181365542114
2022-12-01 14:52:21,348: Loss after epoch 25: 0.03226034692488611
2022-12-01 14:52:23,893: Loss after epoch 30: 0.0314512075856328
2022-12-01 14:52:26,381: Loss after epoch 35: 0.03138935402967036
After the training is done, we can apply our trained model to the input data:
[5]:
reduced = dr.apply(mnist_data[:num_items])
Now we can plot the dimensionality-reduced version of the data that we used for training:
[6]:
paradime.utils.plotting.scatterplot(reduced, mnist.targets[:num_items])
[6]:
<AxesSubplot:>
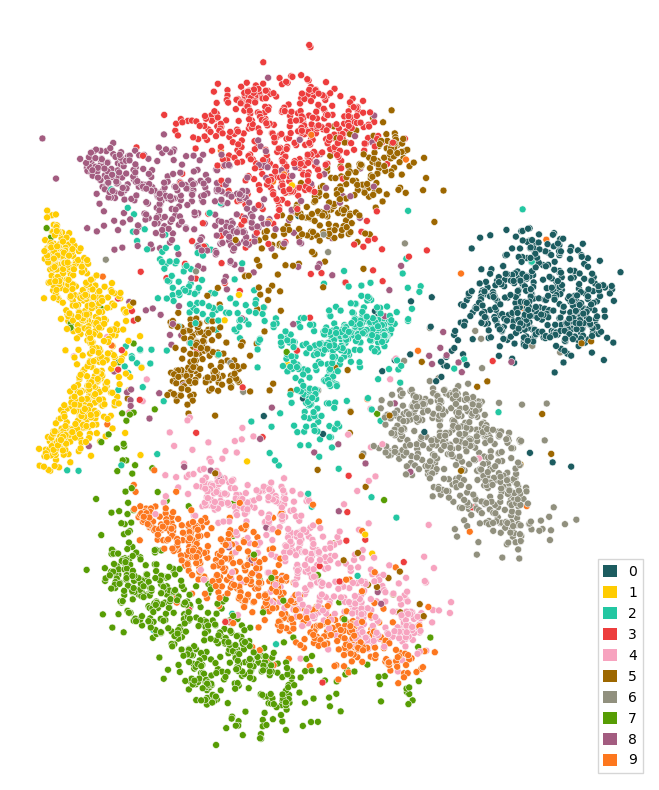
Because ParaDime models are parametric, you can easily apply the trained model to the whole MNIST dataset, even though our routine only ever saw a small subset of it:
[7]:
paradime.utils.plotting.scatterplot(dr.apply(mnist_data), mnist.targets)
[7]:
<AxesSubplot:>

If you want to configure our own ParaDime routines, you will need to get an understandin of what was going on behind the scenes. The output log might have given you a first idea about the different parts and steps involved in a routine. All the details are explained in the section about the Building Blocks of a ParaDime Routine.